Instructor is All You Need: My Review of the Instructor LLM Library by Jason Liu
With numerous LLM libraries available, such as Langchain, CrewAI, Haystack, and Marvin AI, the question arises: what makes Instructor stand out as an llm library? Find out in this blog post.
Following the latest AI Tinkeres Berlin Meetup, where I witnessed a speedrun of very cool AI demos, I couldn't help but dive back into the chaotic world of LLM libraries. It's a realm where developers like me are on a never-ending quest to find the best library to help them build the first 1 billion dollar company.
After trying Langchain, CrewAi and Marvin AI, I started to like Instructor so much that I wanted to share my thoughts on why I personally started using it more and more for all my personal projects like BacklinkGPT.
Let's start by understanding what the instructor library is, by checking out the "H1" of the docs.
Instructor makes it easy to reliably get structured data like JSON from Large Language Models (LLMs) like GPT-3.5, GPT-4, GPT-4-Vision, including open source models like Mistral/Mixtral from Together, Anyscale, Ollama, and llama-cpp-python.
By leveraging Pydantic, Instructor provides a simple, transparent, and user-friendly API to manage validation, retries, and streaming responses.
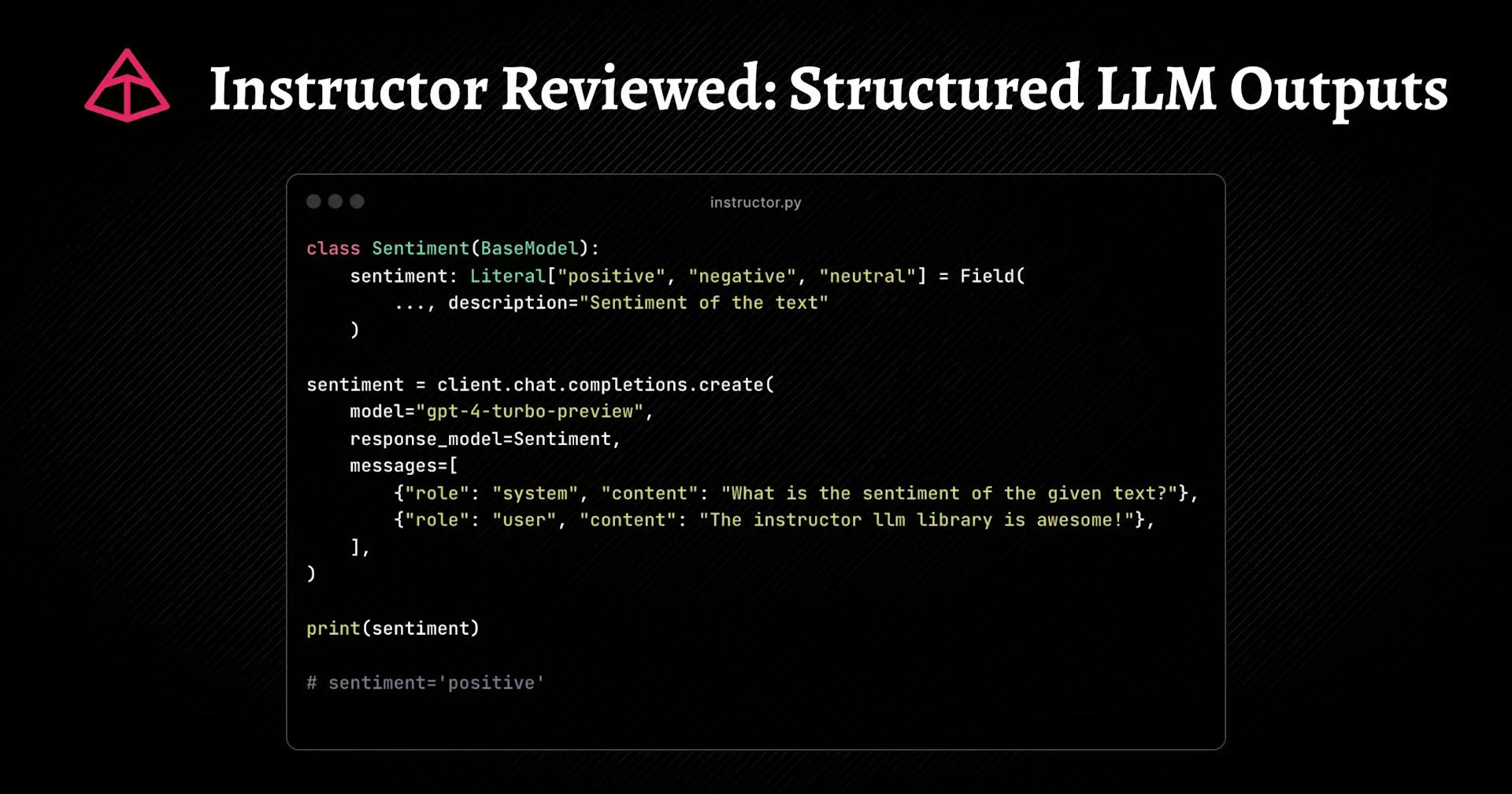
Define a Pydantic model for the output and call the completions endpoint.
class Sentiment(BaseModel): sentiment: Literal["positive", "negative", "neutral"] = Field( ..., description="Sentiment of the text" )
Call the completions endpoint and simply pass in the Sentiment model:
sentiment = client.chat.completions.create( model="gpt-4-turbo-preview", response_model=Sentiment, messages=[ {"role": "system", "content": "What is the sentiment of the given text?"}, {"role": "user", "content": "The instructor llm library is awesome!"}, ],)print(sentiment)# sentiment='positive'
So, if you believe like Guillermo Rauch that the upcoming AI applications will be frontend-first and built by AI Typescript Engineers, Instructor has you covered:
Install Instructor and its dependencies
pnpm add @instructor-ai/instructor zod openai
Import all dependencies and define the client
import Instructor from '@instructor-ai/instructor'import OpenAI from 'openai'import { z } from 'zod'const oai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY ?? undefined, organization: process.env.OPENAI_ORG_ID ?? undefined,})const client = Instructor({ client: oai, mode: 'FUNCTIONS',})
const SentimentSchema = z.object({ // Description will be used in the prompt sentiment: z .literal('positive') .or(z.literal('negative').or(z.literal('neutral'))) .describe('The sentiment of the text'),})
Again call the completions endpoint with the SentimentSchema:
async function main() { const sentiment = await client.chat.completions.create({ messages: [ { role: 'system', content: 'What is the sentiment of the given text?' }, { role: 'user', content: 'The instructor llm library is awesome!' }, ], model: 'gpt-3.5-turbo', response_model: { schema: SentimentSchema, name: 'Sentiment', }, }) console.log({ sentiment })}main()// { sentiment: { sentiment: 'positive' } }
I'm not totally sold on the idea that future AI engineers will be TypeScript engineers, but I have to say Instructor.js worked like a charm with Next.js. If you're wondering why I went with Next.js in the first place, I've got a whole post about it:
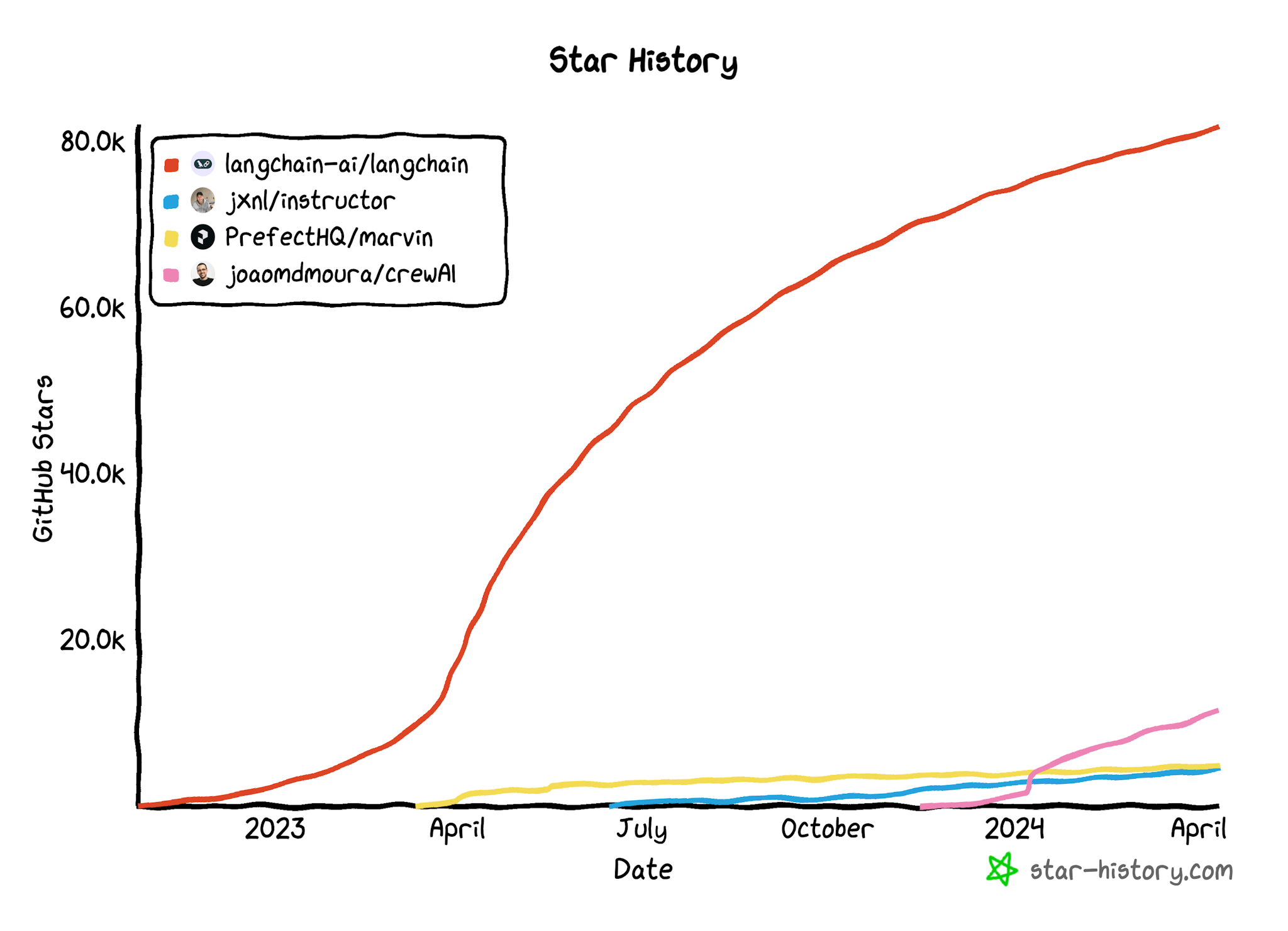
If you look at the vanity metric of popularity via GitHub Stars, you'll see that Instructor has around 4.4k stars, making it a hidden champion compared to more popular libraries like Langchain or CrewAi.
While Instructor may not be the most popular library at the moment, its simplicity, data validation capabilities, and growing community make it a compelling choice for developers looking to integrate LLMs into their projects. Let's dive deeper into the reasons why Instructor is a promising tool and why you might want to consider using it.
Simplicity is one of Instructor's key advantages. Although libraries such as Langchain and CrewAi offer quick starts with pre-built prompts and abstractions, they can become harder to customize as your needs evolve.
Instructor takes a different approach by patching the core OpenAI API. This makes it intuitive for developers already familiar with the OpenAI SDK, while providing flexibility and control as projects scale.
Instructor is to the OpenAI API what Drizzle ORM is to SQL. It enhances the standard OpenAI API to be more developer-friendly and adaptable. By building on existing standards, Instructor flattens the learning curve, letting developers focus on creating powerful LLM applications.
Just as reference implementing the Sentiment classifyer in Langchain just feels more verbose:
from langchain.output_parsers import PydanticOutputParserfrom langchain.prompts import PromptTemplatefrom langchain_core.pydantic_v1 import BaseModel, Field, validatorfrom langchain_openai import OpenAImodel = OpenAI(temperature=0.0)class Sentiment(BaseModel): sentiment: Literal["positive", "negative", "neutral"] = Field( ..., description="Sentiment of the text" )parser = PydanticOutputParser(pydantic_object=Sentiment)prompt = PromptTemplate( template="What is the sentiment of the given text?\n{format_instructions}\n{query}\n", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()},)# And a query intended to prompt a language model to populate the data structure.chain = prompt | model | parseroutput = chain.invoke({"query": "The instructor llm library is awesome!"})sentiment = parser.parse(output)print(sentiment)
Data validation is crucial for production-ready LLM applications. Instructor leverages powerful libraries like Pydantic and Zod to ensure that the outputs from language models conform to predefined schemas. This guarantees a level of reliability that is essential when deploying LLMs in real-world scenarios.
By validating the structure and content of LLM responses, developers can have confidence that the results are not hallucinated or inconsistent. Instructor's validation capabilities help catch potential issues early in the development process, reducing the risk of unexpected behavior in production.
As highlighted in the article "Good LLM Validation is Just Good Validation", Instructor's client.instructor.from_openai(OpenAI()) method provides a convenient way to integrate validation into your LLM pipeline. This approach ensures that your application can handle the dynamic nature of LLM outputs while maintaining the necessary safeguards for reliable operation.
One practical example where I used this is for creating SEO Meta Descriptions.
As a reference, here are the optimal length requirements:
Meta Title: 50-60 characters
Meta Description: 150-160 characters
With these requirements in mind I can use Pydantic to generate a meta description schemafor a blog post:
class Metadata(BaseModel): meta_title: str = Field( ..., min_length=50, max_length=60, description="Meta Title between 50-60 characters. Should be concise, descriptive and include primary keyword.", ) meta_description: str = Field( ..., min_length=150, max_length=160, description="Meta Description between 150-160 characters. Should be compelling, summarize the page content and include relevant keywords naturally.", )meta_descrioption = client.chat.completions.create( model="gpt-4", max_retries=3, # Retry the request 3 times response_model=Metadata, messages=[ {"role": "system", "content": content}, ],)
Calling this code without the max_retries=3 parameter resulted in the following error, showing that the LLM did not exactly follow the given requirements after validating the output with Pydantic.
ValidationError: 1 validation error for Metadatameta_description String should have at most 160 characters [type=string_too_long, input_value='Discover what sets Instr... features and benefits.', input_type=str] For further information visit https://errors.pydantic.dev/2.7/v/string_too_long
After adding the max_retries=3 parameter, the LLM was able to meet the requirements with automatic retries and produced the following output:
{ "meta_title": "Review: Why Instructor Stands Out Among LLM Libraries", "meta_description": "Explore the unique features of Instructor LLM library and what differentiates it from other libraries like Langchain, CrewAI, Haystack, and Marvin AI."}
For another practical use case, check out this example that shows you how to ensure LLMs don't hallucinate by citing resources.
One of the key benefits of using Pydantic with Instructor is the ability to create modular, reusable output schemas. By encapsulating prompts and their expected outputs into Pydantic models, you can easily organize and reuse them across your codebase. This makes managing and sharing prompts a lot easier and more organized than having to copy and paste them around.
Let's look at the famous chain-of-thought prompting technique, a powerful technique that allows LLMs to break down complex problems into smaller, more manageable steps. Here's an example of how you can leverage chain-of-thought prompting with Instructor:
from pydantic import BaseModel, Fieldclass Role(BaseModel): chain_of_thought: str = Field( ..., description="Think step by step to determine the correct title" ) title: strclass UserDetail(BaseModel): age: int name: str role: Role
For more tips on prompt engineering checkout their docs here.
Talking about docs, Instructor just excels at documentation, which is crucial for developer adoption. It provides comprehensive, well-structured API documentation and an extensive cookbook. The cookbook is a valuable resource with recipes for common use cases, serving as a practical reference for developers.
While other frameworks have great examples, Instructor's cookbookstands out by showcasing "real world" examples of how it solves certain problems. I think quite a lot of this is probably due to the fact that the creator, Jason Liu, also works as a freelancer where he's using Instructor himself to solve actual business problems. Here's the list of examples:
Instructor's retry functionality is a game-changer when it comes to using open-source models for extraction tasks. Without Instructor, these models may not be reliable enough to trust their output directly. However, by leveraging Instructor's retry capabilities, you can essentially brute-force these models to provide the correct answer, making them viable options for extraction while still respecting privacy.
The retry mechanism works by automatically re-prompting the model if the output fails to meet the specified validation criteria. This process continues until a valid output is obtained or the maximum number of retries is reached. By incorporating this functionality, Instructor enables developers to utilize open source models that may not be as powerful as their commercial counterparts, but can still produce accurate results through the power of retries.
Finally, all the latest rage is about building agentic workflows, as discussed by Andrew Ng in this video:
Crew.ai is an exciting new library for building AI agents designed for real-world use cases. One of the main challenges I had though is that I just couldn't get the agents to produce consistent output without going off the rails.
Crew.ai provides a great abstraction with an easy-to-use API, but it can still be challenging to reliably steer agents and handle failures gracefully. If a task in a crew fails, there's no straightforward way to pause execution and restart debugging from the latest task.
In contrast, Instructor requires more manual effort to define the desired logic and flow, but it offers greater control and flexibility to build reliable agentic workflows. By carefully designing the task flow and error handling, you can create more predictable and robust agents.
It will be interesting to see how Crew.ai evolves in the future, potentially adopting techniques like memory and other enhancements to improve agent predictability.
I'm excited to explore building more agent-like flows with Instructor in the future to see if it can be used in a similar way to Crew.ai and to understand the level of effort required to emulate Crew.ai's functionality. This exploration will provide valuable insights into the capabilities and limitations of Instructor for creating agentic workflows and help determine its suitability for such use cases.
If you enjoyed this post make sure to check the rest of my blog and follow me on Twitter for more posts like this.