For my SaaS backlinkgpt.com (AI powered backlink building), I need to scrape website content. Sounds, easy right. It took my quite some time to figure out on how to piece together Playwright, FastAPI, OpenAPI, TypeScript, and Next.js. Here's the story.
While it's tempting to think scraping is as easy as sending a request using Javascript's fetch or Python's requests, the reality is different. Modern websites often use Javascript to render content dynamically, meaning a straightforward fetch often won't capture everything. The real challenge is to scrape sites that depend heavily on dynamic content loading techniques.
A headless browser, as the name suggests, operates without a graphical interface. It can interact with web pages, execute JavaScript, and perform tasks similar to a standard browser - all without user visibility. Popular choices include Puppeteer (JavaScript) and Selenium and Playwright, which caters to multiple languages, including Python.
My hope was that running a headless browser on Vercel was straight forward. Turns out it was not. I soon ran into a few issues regarding bundle size and memory limits.
To run them, you must connect to a browser instance via websockets. Browserless.io is one option and has a good tutorial on it.
So I just went ahead and created a route, which would allow me to use the Browserless API and scrape the content:
import { SScrapingResult, SWebsiteInfoInput, SWebsiteInfoOutput } from '@lib/zod-models'import { NextResponse } from 'next/server'import { z } from 'zod'export const runtime = 'edge'export async function POST(request: Request) { const data = await request.json() const startTime = Date.now() const parsedData = SWebsiteInfoInput.parse(data) const apiTOken = process.env.BROWSERLESS_API_TOKEN if (!apiTOken) throw new Error('No BROWSERLESS_API_TOKEN environment variable set') const url = `https://chrome.browserless.io/scrape?token=${apiTOken}` const scrapingUrl = parsedData.url const keyword = parsedData.keyword const body = { url: scrapingUrl, elements: [ { selector: 'body', timeout: 0, }, { selector: 'title', timeout: 0, }, { selector: "meta[property='og:title']", timeout: 0, }, { selector: "meta[property='og:description']", timeout: 0, }, { selector: "meta[property='og:image']", timeout: 0, }, { selector: "link[rel='icon']", timeout: 0, }, ], } const response = await fetch(url, { method: 'POST', body: JSON.stringify(body), headers: { 'Content-Type': 'application/json' }, }) console.log(`Fetch completed in ${(Date.now() - startTime) / 1000} seconds`) if (!response.ok) throw new Error('Error in fetch request') const result = await response.json() function transformToWebsiteInfoOutput(parsedResult: z.infer<typeof SScrapingResult>) { // Initialize empty result let output: Partial<z.infer<typeof SWebsiteInfoOutput>> = {} // Loop over each data item in parsedResult for (const item of parsedResult.data) { if (item.selector === 'body') { output.bodyText = item.results[0]?.text } else if (item.selector === 'title') { output.pageTitle = item.results[0]?.text } else { const attr = item.results[0]?.attributes?.find((a) => a.name === 'content') if (attr) { if (item.selector === "meta[property='og:title']") { output.metaTitle = attr.value } else if (item.selector === "meta[property='og:description']") { output.metaDescription = attr.value } else if (item.selector === "meta[property='og:image']") { output.metaImageUrl = attr.value } else if (item.selector === "link[rel='icon']") { output.faviconImageUrl = attr.value } } } } output.url = scrapingUrl keyword && (output.keyword = keyword) return output } // Parse the result into our SScrapingResult schema const parsedResult = SScrapingResult.parse(result) // Transform the parsed result into our target SWebsiteInfoOutput schema const transformedResult = transformToWebsiteInfoOutput(parsedResult) // Now you can use SWebsiteInfoOutput to parse and validate the transformed result const websiteInfoOutput = SWebsiteInfoOutput.parse(transformedResult) // console.log(JSON.stringify(websiteInfoOutput, null, 2)); return NextResponse.json(websiteInfoOutput)}
Overall, it worked out pretty fine and the scraping was also fairly quick as I shared in this tweet:
While the pricing for Browserless.io was reasonable and I quickly surpassed the free tier's limit of 1,000 scrapes, I remained unsatisfied due to additional challenges.
I encountered two primary challenges with Browserless.io.
When a website presented a cookie consent banner, only this banner was scraped, omitting the actual site content.
I aimed to extract more than just opengraph tags; I wanted to capture the website's text in a more structured format. By converting HTML into markdown, I could reduce token usage for OpenAI's GPT and maintain the crucial structure that plain text would sacrifice.
While addressing these issues with Browserless.io seemed feasible, my Python background made it enticing to use Python Playwright. This approach granted me greater ease in debugging and crafting custom logic, ensuring adaptability for future enhancements.
I've long admired Modal for its unparalleled developer experience in deploying Python apps. While I intend to share a detailed review on its merits soon, feel free to check out my tech stack in the meantime:
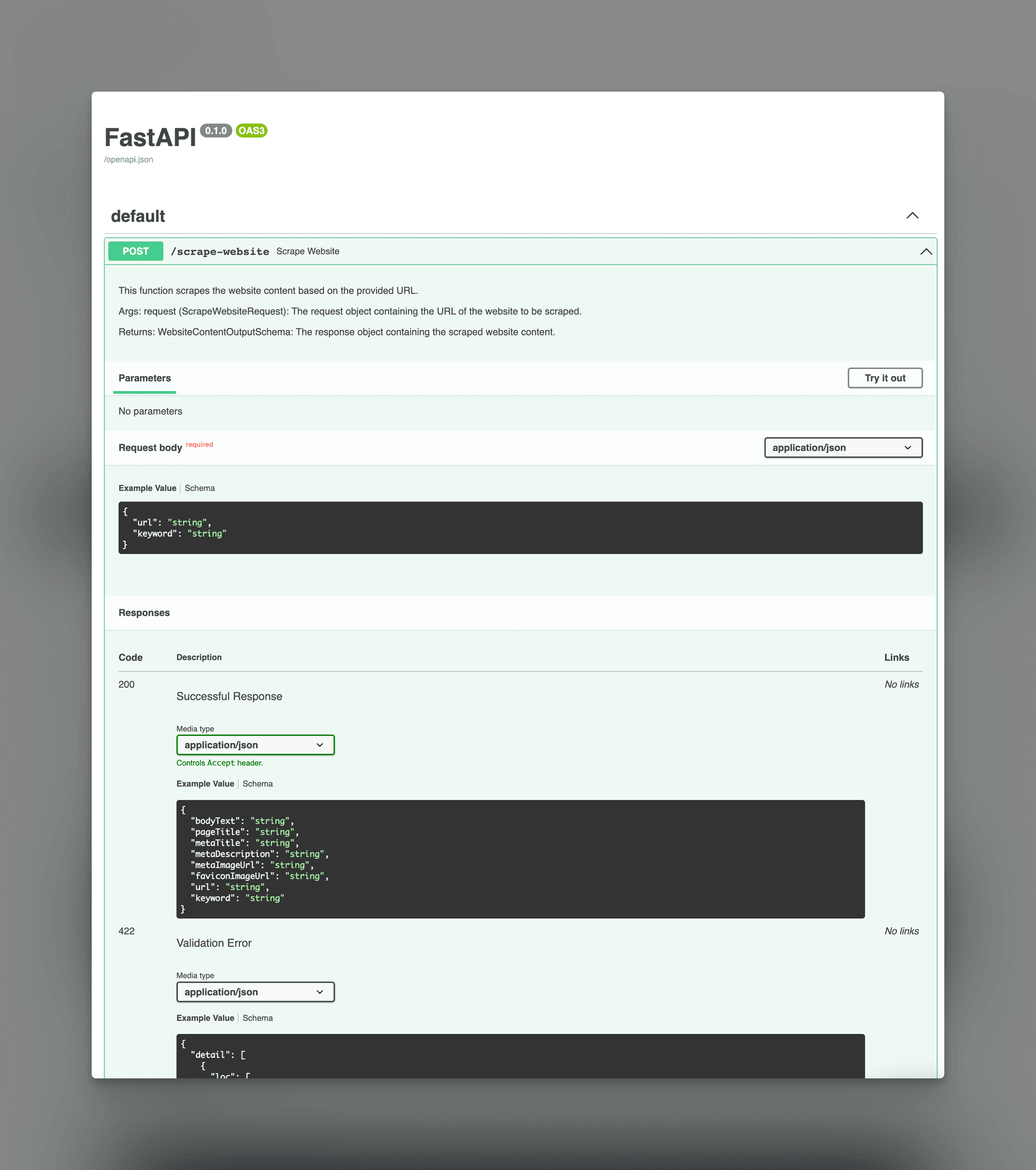
First I created a simple FastAPI app on Modal with the POST route scrape-website. This in turn calls the get_website_content function which takes care of parsing the HTML with Beautiful Soup and converting the HTML content to Markdown with html2text:
"""This module defines the FastAPI application and its endpoints.It includes the endpoint for scraping a website and potentially an endpoint for finding contacts.The application is wrapped with a stub function for deployment."""from typing import Anyfrom common import ENV, image, secret, stubfrom fastapi import FastAPIfrom modal import asgi_appfrom models import ScrapeWebsiteRequest, WebsiteContentOutputSchemafrom scraper import get_website_contentweb_app = FastAPI()@web_app.post("/scrape-website", response_model=WebsiteContentOutputSchema)async def scrape_website(request: ScrapeWebsiteRequest) -> Any: """ This function scrapes the website content based on the provided URL. Args: request (ScrapeWebsiteRequest): The request object containing the URL of the website to be scraped. Returns: WebsiteContentOutputSchema: The response object containing the scraped website content. """ content = await get_website_content(request.url) if request.keyword: content = content.copy(update={"keyword": request.keyword}) return content@stub.function(image=image, secret=secret)@asgi_app(label=f"backlinkgpt-fast-api-{ENV}")def fastapi_app(): """ This function returns the FastAPI application instance. Returns: FastAPI: The FastAPI application instance. """ return web_app
One very known feature of FastAPI is its ability to generate OpenAPI (formerly known as Swagger) documentation for your API out of the box. This documentation not only serves as a great tool for understanding and testing your API endpoints but also provides a JSON schema that can be utilized to generate client libraries in various languages, including TypeScript.
I thought doing so was quite easy, especially since Sebastián Ramírez even wrote some amazing docs on how to do it:
There are many tools to generate clients from OpenAPI. A common tool is OpenAPI Generator. If you are building a frontend, a very interesting alternative is openapi-typescript-codegen.
Turns out I tried too many tools and code generators and was quite amazed on how many new ones are built, but there's not one single super well working one. Here's what I found.
openapi-zod-client: Sadly uses axios and I did not want an additonal dependencies. Also all the functions are in snake case and customizing them was a bit confusing to me since I never used handlebars.
Fern: Looks like a cool startup but a bit of an overkill. Also creating more yaml and custom things was too much work, since I wanted to keep it simple.
/** * This file was auto-generated by openapi-typescript. * Do not make direct changes to the file. */export interface paths { '/scrape-website': { /** * Scrape Website * @description This function scrapes the website content based on the provided URL. * * Args: * request (ScrapeWebsiteRequest): The request object containing * the URL of the website to be scraped. * * Returns: * WebsiteContentOutputSchema: The response object containing the scraped website content. */ post: operations['scrape_website_scrape_website_post'] }}export type webhooks = Record<string, never>export interface components { schemas: { /** HTTPValidationError */ HTTPValidationError: { /** Detail */ detail?: components['schemas']['ValidationError'][] } /** * ScrapeWebsiteRequest * @description A Pydantic model representing the request schema for scraping a website. */ ScrapeWebsiteRequest: { /** * Url * @description The URL of the website to be scraped. */ url: string /** * Keyword * @description The keyword to be searched on the website. */ keyword?: string } /** ValidationError */ ValidationError: { /** Location */ loc: (string | number)[] /** Message */ msg: string /** Error Type */ type: string } /** * WebsiteContentOutputSchema * @description A Pydantic model representing the output schema for website content. */ WebsiteContentOutputSchema: { /** * Bodytext * @description The body text of the website. */ bodyText: string /** * Pagetitle * @description The title of the webpage. */ pageTitle: string /** * Metatitle * @description The meta title of the webpage. */ metaTitle?: string /** * Metadescription * @description The meta description of the webpage. */ metaDescription?: string /** * Metaimageurl * @description The meta image URL of the webpage. */ metaImageUrl?: string /** * Faviconimageurl * @description The favicon image URL of the webpage. */ faviconImageUrl?: string /** * Url * @description The URL of the webpage. */ url: string /** * Keyword * @description The keyword to be searched on the website. */ keyword?: string } } responses: never parameters: never requestBodies: never headers: never pathItems: never}export type $defs = Record<string, never>export type external = Record<string, never>export interface operations { /** * Scrape Website * @description This function scrapes the website content based on the provided URL. * * Args: * request (ScrapeWebsiteRequest): The request object containing * the URL of the website to be scraped. * * Returns: * WebsiteContentOutputSchema: The response object containing the scraped website content. */ scrape_website_scrape_website_post: { requestBody: { content: { 'application/json': components['schemas']['ScrapeWebsiteRequest'] } } responses: { /** @description Successful Response */ 200: { content: { 'application/json': components['schemas']['WebsiteContentOutputSchema'] } } /** @description Validation Error */ 422: { content: { 'application/json': components['schemas']['HTTPValidationError'] } } } }}
With everything set up, I wanted to ensure that our frontend could seamlessly interface with our backend without having to juggle different URLs or face CORS issues. To do this, I turned to the rewrites feature in Next.js, which provides a mechanism to map an incoming request path to a different destination path.
Here's how I configured the rewrites in the next.config.js:
async rewrites() { const fastApiBaseUrl = process.env.NEXT_PUBLIC_FAST_API_BASE_URL; if (!fastApiBaseUrl) { throw new Error('Please set the NEXT_PUBLIC_FAST_API_BASE_URL environment variable'); } return [ { source: "/ingest/:path*", destination: "https://eu.posthog.com/:path*", }, { source: "/fast-api/:path*", destination: `${process.env.NEXT_PUBLIC_FAST_API_BASE_URL}/:path*`, } ]; },
The above configuration tells Next.js to forward any request starting with /fast-api to our backend server. This way, on our frontend, we can simply call /fast-api/scrape-website and it will be proxied to our backend on Modal.com.
With these rewrites in place, the integration of frontend and backend was smooth, and my development experience was greatly enhanced. I no longer had to remember or handle different URLs for different environments, and everything just worked.
And that's how I bridged PydanticV2, OpenAPI, TypeScript, and Next.js together. Hope this helps anyone looking to do something similar!
In just 16 breathtaking seconds, @browserless scrapes a website and @langchain delivers summarization, classification, and keyword extraction. All achieved smoothly on @vercel's edge runtime and AI SDK where data streams seamlessly. The future is here, and it's incredibly fast!⚡